
大型语言模型 (LLM) 在推理、语言理解甚至创造性任务中表现出了卓越的能力。然而,一个关键挑战仍然存在:如何有效地整合外部知识。
传统方法(例如微调和检索增强生成 (RAG))存在弊端——微调需要昂贵的再训练,而 RAG 引入了单独的检索模块,这会增加复杂性并阻碍无缝的端到端训练。另一方面,随着知识库的增长,上下文学习变得越来越低效,面临着二次计算扩展,这阻碍了其处理大型存储库的能力。这些方法的比较可以在图 1 中看到。
整合知识的新方法
为了应对这些挑战,我们引入了 知识库增强语言模型 (KBLaM) 一种将结构化知识库集成到预训练的 LLM 中的新方法。KBLaM 不依赖外部检索模块或昂贵的微调,而是将知识编码为连续的键值向量对,使用专门的矩形注意机制将它们有效地嵌入到模型的注意层中,从而以集成的方式隐式执行检索。
我们使用结构化知识库来表示数据,使我们能够 整合知识 并 利用结构。这种设计使其能够随着知识库的大小 线性扩展,同时保持动态更新 而无需重新训练,从而使其比现有方法效率更高。
可扩展、高效、面向未来
KBLaM 的核心设计是将结构化知识集成到 LLM 中,使其更加高效和可扩展。它通过将外部知识库(由实体、属性和值组成的三元组结构的事实集合)转换为 LLM 可以自然处理的格式来实现这一点。这样的知识库可以提供整合、可靠的知识来源。
为了创建这些知识库,我们首先使用小型语言模型提取 JSON 格式的结构化数据。然后我们应用Project Alexandria的概率聚类。一旦我们有了这个结构化知识库,KBLaM 就会遵循三步流程:
1. 知识编码:
使用带有 轻量级线性适配器的预训练句子编码器 将每个知识三元组映射到键值向量对中。从实体名称和属性派生的键向量编码“索引信息”,而值向量捕获相应的属性值。这使我们能够创建 连续、可学习的键值表示。
2. 与 LLM 集成:
这些键值对或 知识标记使用专门的矩形注意结构 增强到模型的注意层中。与平等处理所有标记并具有二次成本的传统 Transformer 模型(例如 GPT-4、Phi 和 Llama)不同,矩形注意力使模型能够以线性成本关注知识,如图 2 所示。与生成语言模型中的标准注意机制(其中每个标记都会关注所有前面的标记)相比,我们的方法引入了一种更高效的结构。在此设置中,语言标记(例如来自用户问题的标记)会关注所有知识标记。但是,知识标记不会互相关注,也不会反过来关注语言标记。这种选择性注意模式显着降低了计算成本,同时保留了模型有效整合外部知识的能力。
这种线性成本对于 KBLaM 的效率至关重要,实际上相当于独立处理每个事实——这一假设适用于大多数事实。例如,模型名称 KBLaM 与该研究是在微软研究院进行的事实之间的关联非常弱。此矩形注意力机制是作为标准注意力机制的扩展而实现的。在训练期间,我们保持基础模型的权重不变,以确保在没有提供任何知识标记时,模型的功能与最初完全相同。
3. 高效的知识检索:
通过这种矩形注意力,模型学习在推理过程中动态地检索相关的知识标记,从而无需单独的检索步骤。

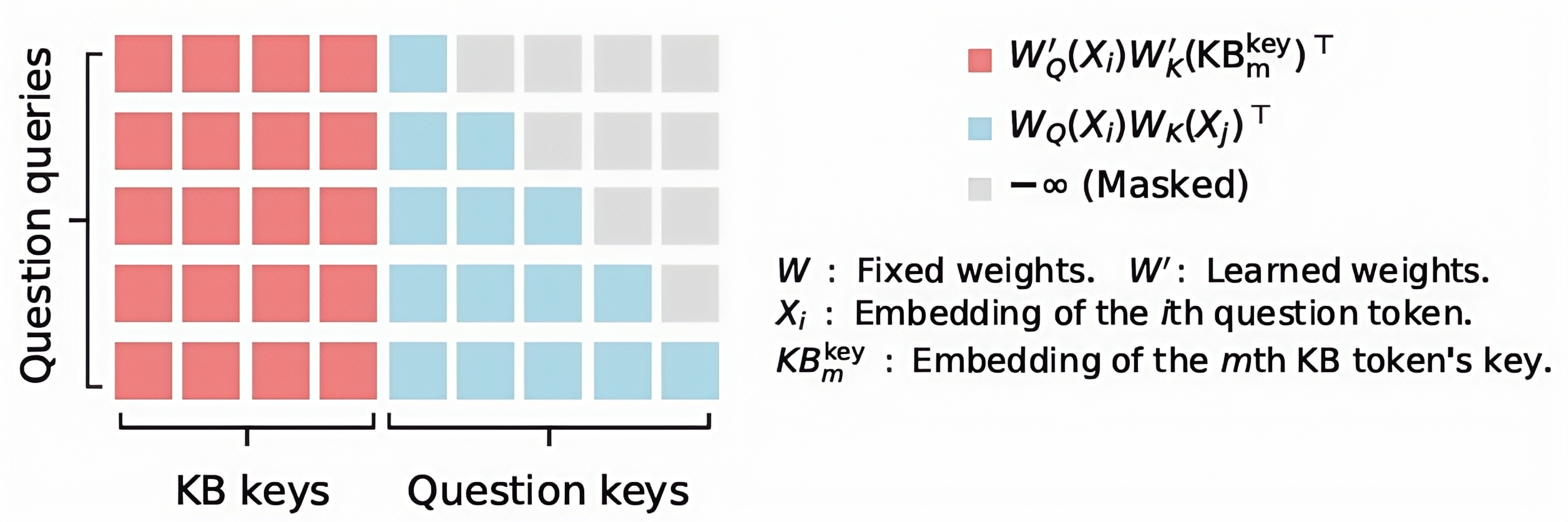
与将检索到的文档块附加到提示的 RAG 不同,KBLaM 允许将知识 直接集成 到模型 中。与上下文学习相比,KBLaM 的矩形注意力保持 线性内存占用,使其对于大型知识库的可扩展性大大提高。
它的效率改变了游戏规则。尽管传统的上下文学习方法由于自注意力开销而难以应对二次方内存增长,但 KBLaM 的线性开销意味着我们可以在上下文中存储更多的知识。实际上,这意味着 KBLaM 可以存储和处理 超过 10,000 个知识三元组,相当于在 单个 **GPU 上存储和处理大约 200,000 个文本标记 **- 这一壮举对于传统的上下文学习来说在计算上是无法承受的。图 3 中可以看到涵盖各种三元组的结果。值得注意的是,它在扩展上下文长度仅为 8K 个标记 的基础模型时实现了这一点。此外,KBLaM 还支持 动态更新:修改 单个知识三元组不需要重新训练或重新计算整个知识库。

增强可解释性和可靠性
KBLaM 的另一个主要优点是其可解释性。与知识注入不透明的上下文学习不同,KBLAM 的 注意力权重 可以清晰地洞察模型如何利用知识标记。实验表明,KBLaM 为相关知识三元组分配了较高的注意力分数,有效地模仿了软检索过程。
此外,如果知识库中缺少必要的信息,KBLaM 可以通过训练示例学习何时不回答问题,从而提高 模型的可靠性。特别是,当知识库大于约 200 个三元组时,我们发现该模型拒绝回答它不了解的问题,其准确度要高于以上下文文本形式提供信息的模型。此功能有助于减少幻觉,这是仅依赖内部知识的 LLM 中常见的问题,从而使响应更加准确和可信。
知识增强型人工智能的未来
KBLaM 代表着将结构化知识整合到 LLM 中迈出了重要一步。通过提供可扩展、高效且可解释的现有技术替代方案,它为能够保持最新状态并提供可靠的知识驱动响应的 AI 系统铺平了道路。在准确性和信任至关重要的领域(例如医学、金融和科学研究),这种方法有可能改变语言模型与现实世界信息的交互方式。
由于人工智能系统越来越依赖动态知识而不是静态模型参数,我们希望 KBLaM 能够成为原始计算能力和现实世界理解之间的桥梁。
然而,在大规模部署之前,仍有一些工作要做。我们目前的模型主要针对事实问答对进行训练,需要进一步研究以将其能力扩展到更复杂的推理任务和不同的知识领域。
为了加快进展,我们正在发布 KBLaM 的代码和数据集 向研究界开放,我们正在计划与 Hugging Face 转换器库进行集成。通过提供这些资源,我们希望激发进一步的研究和采用 可扩展、高效的 LLM 知识增强技术。人工智能的未来不仅仅是生成文本,而是生成准确、适应性强、与不断发展的世界深度融合的知识。KBLaM 是朝着这个方向迈出的一步。